


컬렉션 프레임워크
java.util 패키지
3대 주요 인터페이스
List
순서가 있는 데이터의 집합.
순서가 있으므로 데이터를 구별할 수 있어 중복 허락
ArrayList, LinkedList
Vector는 컬렉션 프레임워크가 나오기 이전부터 존재하는 클래스라 잘 사용하지 않음
Set
순서를 유지하지 않는 데이터의 집합.
순서가 없으므로 데이터를 구별할 수 없어 중복을 허락하지 않음
HashSet, TreeSet
Map
key와 value의 쌍으로 데이터를 관리하는 집합.
순서가 없고 key의 중복 불가. value는 중복 가능
HashMap, TreeMap
Hashtable은 컬렉션 프레임워크가 나오기 이전부터 존재하는 클래스라 잘 사용하지 않음
Collection interface
추가
add(E e)
addAll(Collection<? extends E> c)
조회
contains(Object o)
containsAll(Collection<?> c)
equals()
isEmpty()
isterator()
size()
삭제
clear()
removeAll(Collection<?> c)
retainAll(Collection<?> c)
기타
- toArray()
List의 주요 메서드
추가
add(int index, E element)
addAll(int index, Collection>? exends E> c)
조회
get(int index)
indexOf(Object o)
lastIndexOf(Object o)
listIterator()
삭제
- remove(int index)
수정
- set(int index, E element)
기타
- subList(int fromIndex, int toIndex)
Map의 주요 메서드
추가
put(K Key, V Value)
putAll(Map<? extends K, ? extends V> m)
조회
containsKey(Object key)
containsValue(Object value)
entrySet()
keySet()
get(Object key)
values()
size()
isEmpty()
삭제
clear()
remove(Object key)
수정
put(K key, V value)
putAll(Map<? extends K, ? extends V> m)
자료 구조 비교
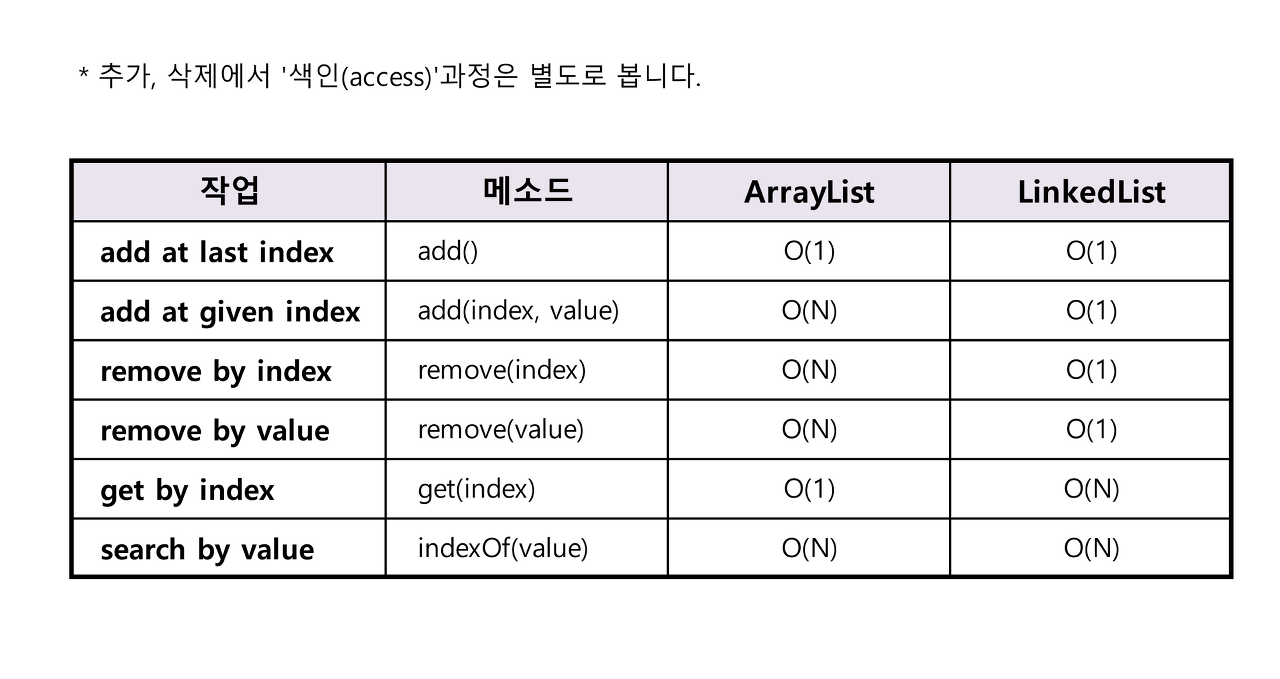
ArrayList vs LinkedList

HashSet vs TreeSet

HashSet
해시 테이블로 구현
추가, 조회, 삭제, 수정 O(1)
정렬이 안 된다
TreeSet
레드-블랙 트리로 구현
데이터 추가, 삭제에는 시간이 걸리지만, 검색과 정렬이 빠르다
이진탐색트리 형태로 데이터 저장
추가, 조회, 삭제, 수정 O(logN)
정렬이 된다
저장 순서가 유지되지는 않는다
LinkedHashMap, LinkedHashSet
데이터의 저장과 순서를 기억하는 경우 사용한다
HashMap, HashSet과 더불어 Doubly-Linked-List로 데이터 삽입 순서를 기록한다
HashMap vs HashSet
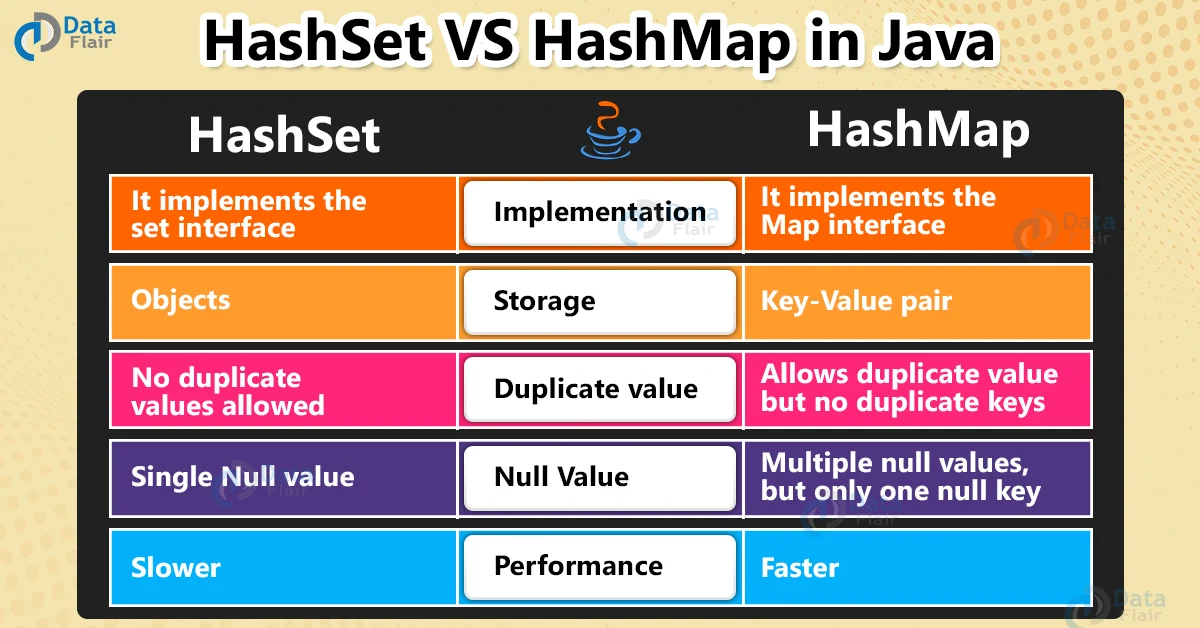
속도 차이가 나는 이유
상대적으로 Map의 Key 값의 해시 코드 변환이 Set의 객체의 해시 코드 계산보다 빠르다
HashSet은 HashMap을 기반으로 구현되어 있다
HashMap vs HashTable

HashMap
보조해시를 사용하기 때문에 해시 충돌이 덜 발생할 수 있어 상대적으로 성능상 이점이 있다
동기화를 지원하지 않으며 thread-safe 하지 않다
IDE의 구현부를 보면, 아래
Hashtable과는 다르게synchronized키워드가 없음// get method public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } // put method public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
HashTable
다른 스레드가 block되고 unblock 되는 대기 시간을 기다려야돼서 상대적으로 느리다
동기화를 지원하며 thread-safe하다
IDE를 이용해 구현부를 보면
synchronized키워드가 붙어있다// get method public synchronized V get(Object key) { // ... 중략 ... } // put method public synchronized V put(K key, V value) { // ... 중략 ... }Null을 허용하지 않는다
ConcurrentHashMap
Hashtable 클래스의 단점을 보완하면서 multi-thread 환경에서 사용할 수 있도록 나온 클래스이다
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> implements ConcurrentMap<K,V>, Serializable { public V get(Object key) {} public boolean containsKey(Object key) { } public V put(K key, V value) { return putVal(key, value, false); } final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; } }위의 코드는 ConcurrentHashMap 클래스의 일부 API 입니다. ConcuurentHashMap에는 Hashtable 과는 다르게 synchronized 키워드가 메소드 전체에 붙어 있지 않습니다.
get() 메소드에는 아예 synchronized가 존재하지 않고, put() 메소드에는 중간에 synchronized 키워드가 존재하는 것을 볼 수 있습니다.
이것을 좀 더 정리해보면 ConcurrentHashMap은 읽기 작업에는 여러 쓰레드가 동시에 읽을 수 있지만, 쓰기 작업에는 특정 세그먼트 or 버킷에 대한 Lock을 사용한다는 것입니다.
참고 자료
